أساسيات Ultralytics YOLO: الجزء الأول
المهام والاستدلال (Tasks & Inference)
التصنيف (Image Classification)

يخرج النموذج قائمة بـ الاحتمالات (probs) لكل صنف ممكن:
| المعرف | الصنف | الاحتمال |
|---|---|---|
| 0 | سيارة (car) | 0.95 |
| 1 | حافلة (bus) | 0.03 |
| 2 | شخص | 0.01 |
| … | … | … |
من هو الفائز؟ (مفهوم الـ top1)
تخيل أن هناك سباقاً بين الأصناف داخل عقل YOLO:
- المتسابق الأول (سيارة): وصل بنسبة ثقة 95%.
- المتسابق الثاني (حافلة): تعثر ووصل بنسبة 3%.
- المتسابق الثالث (كلب): بعيد جداً بنسبة 2%.
إذن، من هو الـ top1؟ هو “السيارة” لأنها صاحبة أعلى نسبة.
Tip
مثال واقعي: لو سألت طفلاً “ما هذا؟” وقال لك: “أنا متأكد بنسبة كبيرة أنها قطة، وبنسبة بسيطة ربما تكون نمر”، فإن إجابته النهائية (قطة) هي الـ top1.

::::
تقوم مكتبة Ultralytics بتسهيل الأمر وتحسب النتيجة النهائية فوراً:
probs: قائمة الاحتمالات لجميع الأصناف.probs.top1→0: رقم (ID) الصنف الفائز (الأعلى احتمالاً).probs.top1conf→0.95: نسبة الثقة في هذه الإجابة (95%).
:::::
مثال: مخرجات التصنيف

الإحداثيات: من المركز للأطراف

كيف نحصل على أطراف المربع؟ إذا عرفنا نقطة المركز، نقوم بطرح نصف العرض للحصول على الطرف الأيسر، وجمع نصف العرض للطرف الأيمن:
\[ \begin{align*} x_{min} &= cx - \frac{w}{2} = 7.5 - 4.0 = 3.5 \\ y_{min} &= cy - \frac{h}{2} = 7.5 - 3.5 = 4.0 \\ x_{max} &= cx + \frac{w}{2} = 7.5 + 4.0 = 11.5 \\ y_{max} &= cy + \frac{h}{2} = 7.5 + 3.5 = 11.0 \end{align*} \]
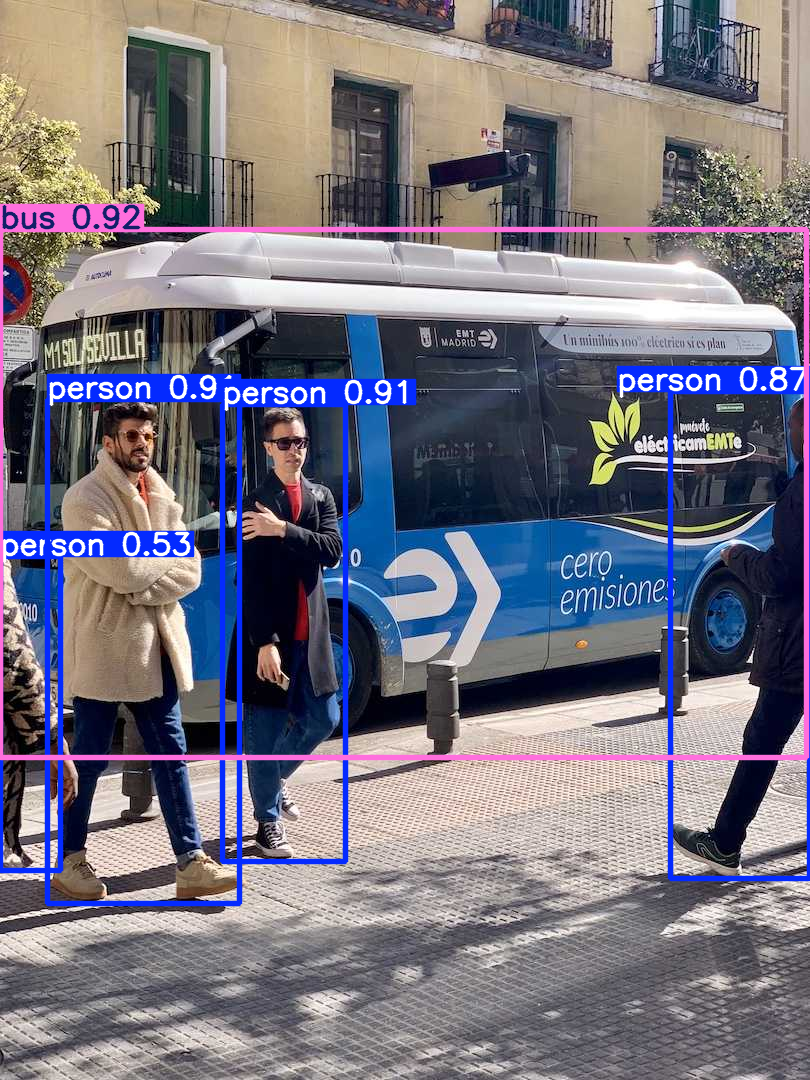
مثال: مخرجات الاكتشاف
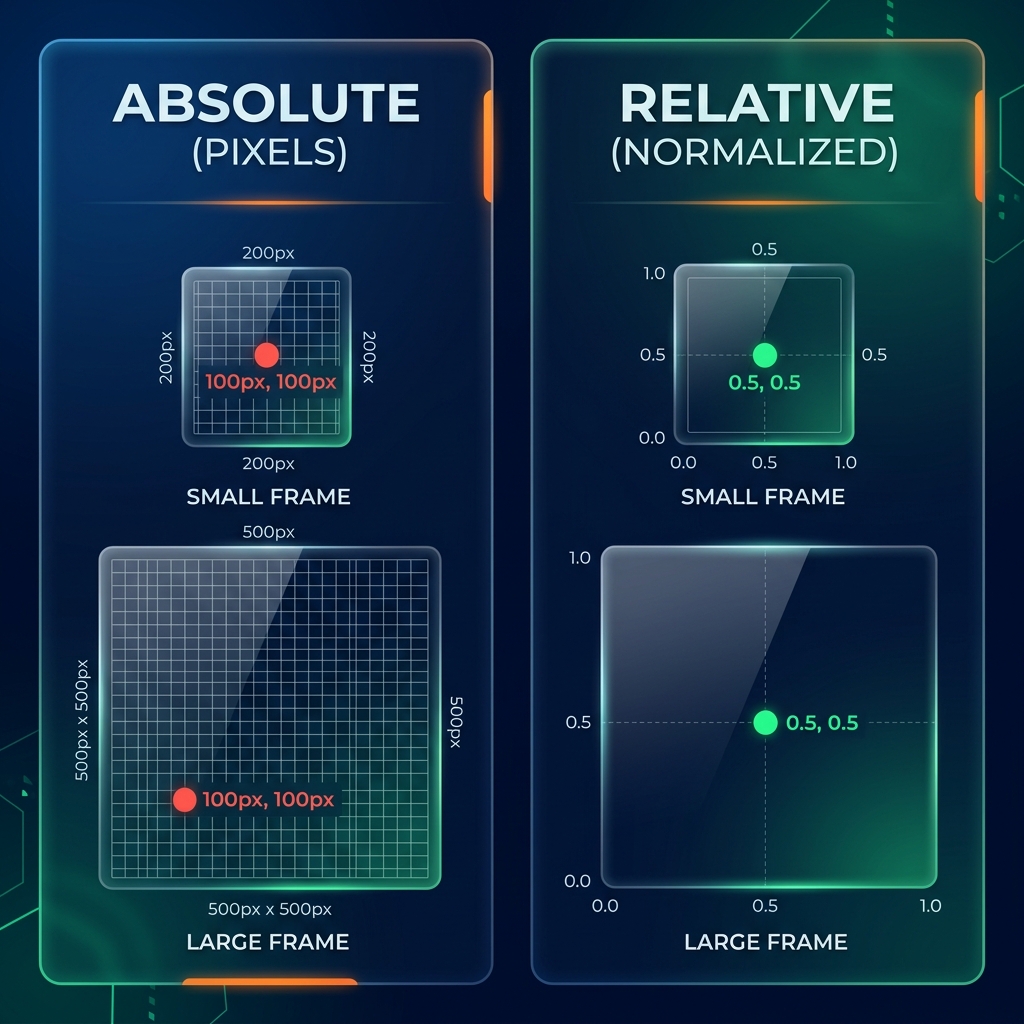
مشكلة “اختلاف أحجام الصور”
تخيل لو قلت لك: “ارسم نقطة على بعد 5 سم من حافة الورقة”. - لو الورقة صغيرة (A5)، النقطة ستكون في المنتصف. - لو الورقة كبيرة (A3)، النقطة ستكون قريبة جداً من الحافة!
هذه مشكلة! الذكاء الاصطناعي سيحتار لو تغير حجم الصورة (مثل الفرق بين جودة 4K وصورة واتساب).
التجزئة (Instance Segmentation)

هنا لا نرسم مربعاً عادياً، بل نرسم شكل السيارة بدقة بيكسل ببيكسل!
- قناع البيكسل (Mask Tensor): جدول يحمل رقم
1إذا كان البيكسل يمثل السيارة، و0إذا كان يمثل الخلفية. - الإحداثيات: زوايا المضلع \((x, y)\) التي تشكل حدود السيارة بدقة.
conf: نسبة الثقة.cls: الصنف (سيارة).
مثال: مخرجات التجزئة

الهيكل (Pose Estimation)

هنا نتعرف على “مفاصل” الجسم وتشكيله (مفيد جداً لتحليل الحركة والرياضة):
x, y: الإحداثيات لكل مفصل (مثل الأنف، المرفق، الركبة).kp_conf: نسبة التأكد من مكان هذا المفصل بالذات.conf: نسبة التأكد من وجود الشخص كاملاً.cls(0): دائماً الصنف 0 (شخص) في نماذج الهيكل.
مثال: مخرجات الهيكل

المربعات المائلة (OBB)

هذه مربعات إحاطة ولكن “مائلة”! مفيدة جداً في صور الأقمار الصناعية والطائرات بدون طيار (الدرون).
cx, cy: نقطة المركز.wوh: العرض والارتفاع.angle: زاوية الدوران.conf: نسبة الثقة.cls: رقم الصنف.
مثال: مخرجات المربعات المائلة (OBB)
